Remerciements
- Table des matières
- Introduction
- 1. L'entreprise: eProcess
- 2. MPEG: normes, compression et application
-
- 2.1. Principes de compression du MPEG 1
- 2.2. Principes du MPEG 2
-
- 2.2.1. Différences entre MPEG1 et MPEG2
- 2.2.2. Encodage en 2 passes
- 2.3. Principes du MPEG4
- 2.4. Etude industrielle du MPEG4 et du DivX
-
- 2.4.1. Les courants normatifs du MPEG-4
- 2.4.2. Les implémentations DivX
- 2.4.3. Décodage hard du MPEG-4
- 2.4.4. Diffusion du MPEG 4
- 2.4.5. Conclusion de l'étude industrielle
- 3. Estimation de mouvement
-
- 3.1. principe de l'estimation de mouvement
- 3.2. Estimation de mouvement par bloc carré régulier
-
- 3.2.1. Calcul de l'erreur résiduelle
- 3.2.2. Compensation de mouvement
- 3.3. Algorithmes de Block Matching
-
- 3.3.1. Méthode Full Search (FS)
- 3.3.2. Méthode Three Step Search (TSS)
- 3.3.3. Recherche en Diamant
- 3.3.4. Algorithmes 2D-logarithmiques
- 3.3.5. méthode PHODS
- 3.3.6. Zonal Based Algorithm
- 3.4. Estimation de mouvement par segmentation
- 4. Test de Qualité des implémentations DivX
-
- 4.1. Protocole de test
-
- 4.1.1. mesure de l'erreur
- 4.1.2. Algorithmes testés
- 4.2. mise en oeuvre des tests
-
- 4.2.1. Compression des flux
- 4.2.2. Comparaison des flux
- 4.3. Résultats
- 4.4. Interpretation des résultats
- 4.5. Prospectives
- Conclusion
- Bibliographie
- A. Annexes: Histogrammes des erreurs
- B. Annexe: fichier de script python
- Liste des tableaux
- 4-1. erreurs des moindres carrés
- Liste des illustrations
- 2-1. Sous échantillonnage en 4:2:0
- 2-2. Corrélation des pixels dans un bloc
- 2-3. Bloc 8*8 pixels avant DCT
- 2-4. Bloc 8*8 pixels après DCT
- 2-5. Algorithme zigzag
- 2-6. Coefficients de la DCT
- 2-7. Formule analytique de la DCT
- 2-8. Transformée DCT inverse
- 3-1. Recherche de pattern dans l'image précédente
- 3-2. Erreur résiduelle entre deux blocs de 16*16 pixels
- 3-3. Méthode Full Search: Nombre d'instruction par seconde
- 3-4. Méthode Full Search: Fenêtre de recherche
- 3-5. Approximation de l'erreur (cf sad.pdf)
- 3-6. Algorithme "three step search":
- 3-7. Algorithme "Diamond search":
- 3-8. Exemple de recherche 2D-logarithmique
- 3-9. Compensation de mouvement avec segmentation
- 3-10. Vecteurs de mouvement avec des blocs de taille fixe
- 3-11. Vecteurs de mouvement avec des blocs découpés en quadtree
- 4-1. Protocole de test
- 4-2. Critère des moindres carrés
- 4-3. Différence de deux images d'un même flux, espacées de 15 images.
- 4-4. Différence (amplifiée) entre deux images encodées avec des codecs différents
- 4-5. Exemple d'histogramme avec gracePlot
- 4-6. Différence d'histogrammes
- 4-7. Sommes d'histogrammes
- 4-8. Comparaison de l'erreur issue de Xvid sur la séquence tennis:
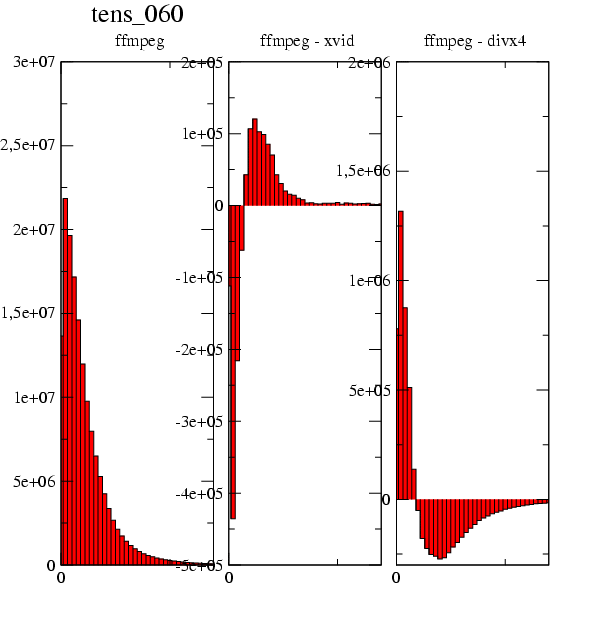
- 4-9. Comparaison de l'erreur issue de FFmpeg sur la séquence mobile:
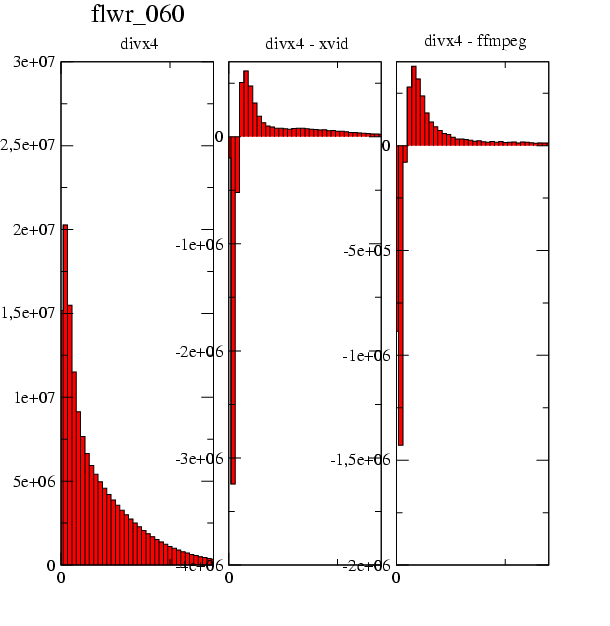
- 4-10. Comparaison de l'erreur issue de DivX4 sur la séquence flower:
- A-1. Xvid, séquence tennis
- A-2. Xvid, séquence susie
- A-3. Xvid, séquence mobile
- A-4. Xvid, séquence flower
- A-5. Ffmpeg, séquence tennis
- A-6. Ffmpeg, séquence susie
- A-7. Ffmpeg, séquence mobile
- A-8. Ffmpeg, séquence flower
- A-9. Divx4, séquence tennis
- A-10. Divx4, séquence susie
- A-11. Divx4, séquence mobile
- A-12. Divx4, séquence flower
- Liste des exemples
- 2-1. exemple d'analyse d'un fichier MPEG1 (durée: 3,44 secondes)
Chapitre 2. MPEG: normes, compression et application
2.1. Principes de compression du MPEG 1
L'algorithme MPEG-1 [1] fut originellement conçu pour des taux de transfert de CD simple vitesse (1,5 Mbit/s soit 200 Ko/s). Il présente une qualité semblable au VHS.
Plus qu'une compression particulière, c'est la compostion de plusieurs algorithmes de compression qui font la qualité du MPEG. Nous voyons dans cette partie les principes du MPEG1, qui sont repris ou améliorés dans les versions suivantes.
2.1.1. Sous échantillonage
Y = (0.257 * R) + (0.504 * G) + (0.098 * B) + 16
Cr = V = (0.439 * R) - (0.368 * G) - (0.071 * B) + 128

2.1.2. Utilisation de la redondance spatiale




2.1.2.2. Application mathématique
On applique la matrice de transformation P sur une matrice de pixels A:B=P.A


les valeurs des c(u) et c(v) étant données par: 1/racine(2) si f=0 et 1 si f>0

2.2. Principes du MPEG 2
Le MPEG2 [1] permet une très bonne qualité de vidéo, nettement supérieure au MPEG1: le framerate est passé à 30 Image par secondes, la résolution est de 720*576 et le débit de 15 Mbit par seconde. L'application la plus connue du MPEG2 est le DVD.
Cette norme est la continuation logique de la norme MPEG-1. Ainsi elle reprend les memes specifications et conserve la compatibilité entre les deux médias. De nouveaux concepts ont cependant été mis en avant.
2.2.1. Différences entre MPEG1 et MPEG2
2.2.2. Encodage en 2 passes
Nous avons vu que le mPEG2 adaptait son bitrate à la complexité de l'image. C'est l'encodage en deux passes qui permet cela [2]. L'encodage en deux passes se déroule de la manière suivante:
-
Première passe: encodage à un bitrate constant. L'algorithme accumule des statistiques sur la complexité des images. Pour chaque image, on fait d'une part une estimation du mouvement: on calcule les variations de luminance d'une image sur l'autre. C'est "l'activité du macrobloc". D'autre part, on estime la complexité des textures. La somme des deux valeurs constitue la complexité de l'image.
-
Deuxième passe: redistribution des bits diponibles sur chaque frame en fonction de la complexité mesurée lors de la première passe. Le but de cette allocation de bit est d'avoir non pas un birate constant mais une qualité visuelle constante. Il est évident qu'une scène très précise et rapide nécessite plus de bits qu'une scène très simple.
l'encodage en deux passes n'est toutefois pas imposé; il est possible d'encoder en temps réel.
2.3. Principes du MPEG4
2.3.1. Extension des normes MPEG1 et MPEG2
Créé en 1998, la norme MPEG4 [1, 3] a pour but de trouver un compromis entre qualité et taille des fichiers. En effet, les flux MPEG1 possédaient une taille raisonnable, mais une mauvaise qualité. Inversement le MPEG2 possède une très bonne qualité mais la taille des fichiers est énorme, en particulier si l'on veut faire circuler ceux ci sur un réseau. Les fichiers MPEG4 sont prévus pour pallier ces deux problèmes, avec un bitrate de 64kBit/s.
Mais au dela de la compression, la norme MPEG4 propose également une nouvelle organisation des flux audio-vidéo, orientée objet. La description des scènes se fait en séparant les objets vidéo ou audio, codés séparémment. Chaque objet pouvant alors interagir avec un autre et évoluer dans différents plans. Un personnage qui parle peut être décomposé en un objet vidéo "personne", et un objet audio "voix", les deux étant synchronisés et ajoutés par dessus l'objet "décors" placé en second plan. Le but de cette décomposition est d'organiser les scènes en mediaobject sur lesquels on peut agir séparemment: codage, édition, transparence, etc. La suppression de la précédente personne est possible, et on arrive alors à la notion d'interactivité, actuellement très prisée. Un autre avantage de ce type de description est la possibilité d'appliquer des techniques de codage adaptées aux différents objets de la scène. Le bitrate et le framerate seront fixés en fonction du besoin.
La norme MPEG4 ne s'arrète pas à la décomposition des scènes en objets, elle propose également les techniques suivantes:
-
division des images en plans [4]. On peut alors séparer les mouvements des différents plans. Par exemple on peut reconstituer le décor de fond, et effectuer des zooms avec des angles différents suivant les scènes. Il suffit de coder une seule fois le décor.
-
La décomposition des visages en maillage fil de fer et texture. On a alors un gain en compression.
-
La possibilité d'insérer des objets synthétiques.
-
Une gestion des profils très précise qui prend en compte les aspects interactivité et diffusion sur un réseau.
2.4. Etude industrielle du MPEG4 et du DivX
2.4.1. Les courants normatifs du MPEG-4
2.4.1.1. MPEG iso
Le courant MPEG 4 initial est celui du Moving Picture Expert Group appartenant au groupe ISO/IEC, créateur des normes MPEG1 et MPEG2. Ils sont les précurseurs de la norme MPEG4. [1, 3]
Le Moving Picture Expert Group ne définit pas d'algorithme d'encodage mais propose simplement des techniques de compression (sans les algorithmes) et la façon dont doit être agencé les données de vidéo, de son et de synchronisation dans le flux MPEG4.
Deux versions de la norme MPEG-4 ISO existent déja:
-
la version 1 approuvée en octobre 1998
-
la version 2 finalisée en décembre 1999
Les versions 3, 4 et 5 sont en cours.
La société MPEG LA travaille en collaboration avec le Moving Expert Picture Group pour représenter ses interêts commerciaux. MPEG LA s'occupe de la gestion des droits de la propriété intellectuelle et des licences du contenu MPEG-4.
2.4.1.2. MPEG-4 Industry Forum
Les principaux membres du MPEG-4 Industry Forum (M4IF) [6] sont: MPEG LA, Microsoft Corporation, Intel Corp., le Fraunhofer Institute IIS-A, DivXNetworks Inc., Motorola, etc (liste non exaustive). C'est une organisation à but non lucratif dont le but est "d'uniformiser la norme et l'utilisation du MPEG4 pour les développeurs, les prestataires de services et les utilisateurs". Le M4IF essaye de promouvoir le MPEG4 dans le milieu industriel et veille au passage du MPEG4 de la norme ISO à l'industrie.
Toutes les implémentations des sociétés membres travaillent donc en relation avec le M4IF, en particulier pour celle de DivXNetworks: DivX5. Le but du M4IF est d'avoir dans la pratique une normalisation des contenus, codeurs et décodeurs MPEG4.
2.4.1.3. ISMA: Internet Streaming Media Alliance
Ce consortium [7] est composé de Apple, Cisco, IBM, Philips, Sun Microsystems, et rassemble également la participation de AOL, Lucent, Dolby (son AAC), Sony, etc. On remarquera que toutes ces sociétés appartiennent également au M4IF. Le but de l'ISMA est de travailler sur les aspects de normalisation des transports de flux sur les réseaux, en particulier sur le streaming..
Ce consortium fournit une norme ainsi qu'un codec: Quicktime 6. Une version beta est diponible pour Mac et Windows; il est optimisé pour les processeurs Motorola G3 et G4. Selon Apple, tous les formats respectant le MPEG-4 iso pour la video et AAC pour l'audio devraient etre décodable par Quicktime 6. De même pour le MPEG-2 lors de la version finale.
2.4.2. Les implémentations DivX
2.4.2.1. le projet mayo
La première implémentation de l'algorithme DivX [8] fut développée en 1999 par Jérôme Rota à Montpellier. Celui ci a ensuite créé le project mayo, site regroupant les algorithmes opensource DivX ainsi que d'autres projets de player vidéo. Ce projet a sorti la première version du DivX: DivX 3.11 alpha, version illégale car piratée sur le codec Microsoft WMV vidéo codec. Une nouvelle version légale est sortie plus tard, remportant un très grand succès: l'agorithme DivX4 ou OpenDivX.
Puis une séparation s'est faite entre les développeurs initiaux du project mayo, désireux d'accelérer le développement des algorithmes, et d'autres personnes voulant continuer l'implémentation opensource.
D'où la création de la société DivXNetworks, reprenant l'activité commerciale des algorithmes en fermant les sources du DivX 4 et en lancant le DivX 5. D'autre part, le développement du codec opensource du projet mayo continue desormais sous le nom xvid. Le site du projet Mayo acceuille maintenant le projet Opendivx sans toutefois mettre à disposition les sources du codec.
2.4.2.2. DivXNetworks
DivXNetworks [9, 10] est donc issu du projet Mayo mais leurs algorithmes ont été complètement repris: ils ne sont pas basés sur le code openDivX. La dernière version du codec DivX est la version 5 qui se décline en deux versions:
-
DivX Video Software. L'utilisation de cet algorithme est gratuit tant qu'elle n'est pas à des fins commerciales. Deux exceptions toutefois: l'utilisation pour les réalisateurs de film ainsi que l'inclusion dans des packages est gratuite.
Il utilise les I-VOP et P-VOP (Video Object Plane, en réalité des frames), permet l'encodage en plusieurs passes, 5 degrés prédéfinis de qualité d'encodage, la détection automatique de scènes (pour l'insertion d'image I), l'insertion automatique ou manuelle des I-frame. La quantification peut être faite en YUV 4.2.0, 24 ou 32 bits RGB, YUV2, UYVY ou YVYU. L'algorithme DivX 5 supporte le MPEG-4 simple profile.
En outre, il fonctionne sur les plateformes Windows, linux, Mac OS et bientôt Pocket PC. DivXNetwork est basé sur le MPEG4 ISO mais est désormais membre du M4IF.
-
DivX Pro Video Software. Cette version est payante (30 Dollars US). A qualité égale, la taille des fichiers est inférieure de 25% avec DivX pro. Dans les améliorations par rapport à l'algorithme DivX, on retrouve les B-Video Object Plane, la global motion compensation et le quarter pixel. Il supporte donc le MPEG-4 advanced simple profile.
Il existe pour cette version un Ad Suported Software nommé GAIN: Gator Advertising & Information Network permettant l'utilisation gratuite de DivX Pro Video Software et diffusant en contre partie de la publicité.
La version 5 de DivX contient encore des bugs. La version 4 est actuellement la plus répandue.
2.4.2.3. Xvid
Xvid [11] est également issu du projet Mayo, mais se différencie de DivX car il est open source. C'est la reprise de opendivx quand les sources de celui ci ont été fermées par DivXNetworks. Il présente les meilleures performances en terme de rapidité de compression. Il ne gère cependant pas les B frames ni la "global motion estimation". Xvid utilise l'algorithme PMVFAST pour la recherche de mouvement (Cf. Chapitre 3: Estimation de mouvement). Contrairement à DivX4, cette implémentation est en constante évolution et constitue la principale alternative aux algorithmes de DivXNetworks.
Il y a deux implémentations de l'algorithme Xvid: Koepi et Nick's codec. Ces algorithmes sont conformes au MPEG4 ISO simple profile.
2.4.2.4. FFmpeg
FFmpeg [12] est un autre projet opensource. Il contient deux parties:
-
FFmpeg: un codeur/décodeur mpeg4 qui supporte le MPEG4 simple profil (pas de B-pictures). Il offre la possibilité de convertir des flux vidéo d'un format à un autre, ou d'encoder en temps réel à 25fps en 352*288. Dans ce cas, les techniques de block matching sont très limitées et effectuent la recherche uniquement pour les motion vector (0,0). FFmpeg est multiformat: il manipule les fichiers MPEG1, H263, Real Video, MPEG4, DivX et MJPEG. Pour la compression en AVI, plusieurs méthodes d'estimation de mouvement sont disponibles: Full search, 2Dlog et PHODS.
-
FFserver: serveur de streaming permettant la diffusion de flux via HTTP. Malheureusement, FFserver ne gère que le program stream et non le transport stream. Il n'y a donc pas la possibilité de gérer la diffusion sur une connexion non fiable: . La diffusion est donc limitée à un réseau local.
Ce projet est récent, comporte moins de fonctionnalités que DivX ou Xvid, mais s'améliore très rapidement et la fonctionnalité serveur de streaming est intéressante.
2.4.3. Décodage hard du MPEG-4
2.4.3.2. Philips Trimédia
Le trimédia permet de traiter des algorithmes classiques utilisés en compression vidéo tels que la DCT. La société 4i2i a par exemple developpé les librairies H.261 et H.263 (mpeg1) pour le trimédia (4i2i H.261 and H.263 Software for Philips Trimedia). En revanche, aucun flux MPEG4 ne peut etre traiter.
2.4.4. Diffusion du MPEG 4
Le MPEG-4 sera t'il le standard pour le streaming ? (NetEconomie).
Chapitre 3. Estimation de mouvement
3.1. principe de l'estimation de mouvement
L'estimation de mouvement [13, 14] va encore améliorer cette technique de codage "delta" en réduisant les différences à coder entre deux images. Pour cela, on essaye pour une image donnée de "prédire" la suivante. En réalité on code l'image actuelle par rapport à des morceaux de l'image précédente. On fait une recherche sur l'image d'avant pour trouver des partitions ressemblantes. Puis on trouve le vecteur de mouvement pour la partition entière.
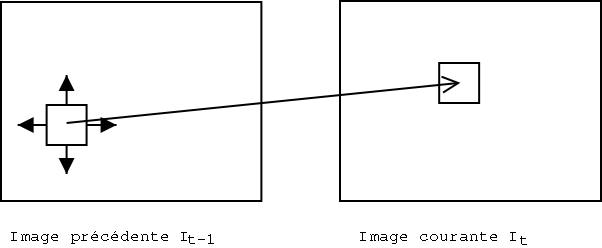
3.2. Estimation de mouvement par bloc carré régulier
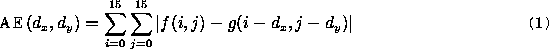
3.3. Algorithmes de Block Matching
3.3.1. Méthode Full Search (FS)

Qu'on peut approximer par 8TPQW², soit une complexité en O(n^4).

La complexité de ce critère est beaucoup moins élevé que le SAD.
3.3.2. Méthode Three Step Search (TSS)
La méthode TSS [15] a été conçue pour réduire la compléxité de l'algorithme FS. On se limite à trois pas pour trouver le meilleur bloc. On cherche le bloc le plus ressemblant dans l'image précédente de la façon suivante:
-
Initialisation: On se place au vecteur de mouvement (0,0). C'est le centre de la recherche.
-
Etape 1: On teste le critère aux alentours du centre à un rayon R1 (8-connexité), et on repère le point qui minimise le critère.
-
Etape 2: On prend le minimum trouvé précédemment comme nouveau centre et on recherche aux alentours de ce point avec un rayon R2 < R1. On reprend le minimum comme centre de la prochaine étape.
-
Etape 3:On renouvelle une troisième fois l'opération avec un rayon R3 inférieur aux deux premiers.

3.3.3. Recherche en Diamant
Diamant simple: La recherche en diamant (Diamond search) [16] débute la recherche au vecteur (0,0). Puis il examine le critère en déplacant la fenêtre sur 9 points disposés en diamant. Une fois le minimum des ces neufs points trouvé, on reprend la recherche avec le minimum précédent comme centre de la nouvelle recherche. On repète l'opération tant que le minimum ne se trouve pas au entre du diamant. Quand on a effectivement le minimum au centre, on effectue une dernière recherche avec un plus petit diamant qui determinera le minimum estimé de l'image.


3.3.6. Zonal Based Algorithm
3.3.6.1. méthode PMVFAST
La méthode PMVFAST [23, 17] correspond au fast motion utilisé dans le MPEG4 et plus partculièrement dans les algorithmes DivX. Il permet une estimation de mouvement rapide et une très bonne qualité visuelle.
3.3.6.1.2. Algorithme
L'algorithme PMVFAST est basé sur une Diamond Search, avec deux tailles de diamant. Algorithme:
Une comparaison de l'algorithme PMVFAST [18] avec l'algorithme de référence Full Search donne les résultats suivants: PMVFAST est 5796 fois plus rapide que FS, avec une perte de 0.15dB de PSNR.
3.4. Estimation de mouvement par segmentation
3.4.1. Principe
La segmentation [19] va permettre de diviser l'image en zone contenant plus de sens. Elle consiste à regrouper des pixels de caractéristiques communes ou proches.
Pour le MPEG, la segmentation est utile car d'une manière générale, dans un flux vidéo, les blocs de pixels se déplacant (les objets, personnages,...) ne sont pas des blocs carrés. La segmentation va permettre de découper les images en régions plus adaptées aux images réelles et par conséquent de mieux exploiter la redondance spatiale des images. L'erreur de mouvement à transmettre sera moindre et on gagnera donc en compression.

Les deux gros avantages de la segmentation sont les suivants:
3.4.2. Algorithmes de segmentation pour la compensation de mouvement
3.4.2.1. segmentation par approximation de blocs carrés
Une première méthode simple de segmentation est d'approximer les blocs par des blocs de référence [5]. Pour cela, on découpe chaque bloc en sous blocs que l'on compare à des patterns de référence. Ces patterns sont établis en fonction des sous blocs les plus rencontrés. Les sous blocs ne peuvent contenir que deux régions au maximum. Puis on minimise le critère des moindres carrés sur les sous blocs de référence pour déterminer quel sous bloc correspond le mieux. On a alors sur toute l'image un ensemble de régions segmentées.
Cet algorithme donne de bons résultats: utilisée avec la méthode de recherche Full Search associée à une décomposition pyramidale de 3 niveaux [21], on obtient un gain en compression de 10% par rapport à la même technique sans segmentation.
3.4.2.2. segmentation par quadtrees

On peut utiliser l'algorithme du quad-tree pour découper l'image [22]. Voici son principe et son application pour l'estimation de mouvement:
On part de blocs relativement grands, et on teste l'erreur résiduelle sur ces blocs. Tant que l'erreur résiduelle est supérieure à un certain seuil, on redécoupe le bloc en quatre. Ainsi si des grands blocs possèdent un vecteur de mouvement uniforme, on aura une erreur résiduelle faible et un seul vecteur devra être transmis.

Chapitre 4. Test de Qualité des implémentations DivX
4.1. Protocole de test
Ceux ci sont intéressants car ils comportent des séquences de translation sur des objets contenant des textures complexes. Cela permet d'évaluer la qualité de l'estimation de mouvement du codec.
Voici une description générale du protocole utilisé pour estimer la qualité de la recherche de mouvement: comparaison des images issues des flux encodés ou non, et mesure de l'erreur.
A partir d'un flux vidéo de référence, on encode celui ci avec les différents encodeurs à tester. Puis on effectue une extraction (sans pertes) des images composants les flux. La mise en correspondance des images permettra d'estimer l'écart des flux encodés avec le flux de départ.

4.1.2. Algorithmes testés
Les trois algorithmes opensource disponible sont les suivants:
4.1.2.1. DivX4Linux
Toutes les implémentations opensources existantes sont issues du même projet: le projet Mayo. La dernière implémentation libre du projet Mayo avant que celui ci ne ferme ses sources est DivX4Linux. C'est le codec DivX4 [10], désormais renommé par DivXNetworks Opendivx (malgré la fermeture des sources).
La méthode de block matching utilisée par divx4 est l'algorithme diamond based algorithm. L'agorithme divx4 implémente le demi et le quart de pixel, qui apporte théoriquement une bonne précision.
4.1.2.2. Xvid
Après la fermeture des sources de DivX4 et la fondation de la société DivXNetworks, le code de Divx4linux a été repris par les partisans de l'opensource, et amélioré. C'est le projet Xvid [11], moins abouti que DivX4 mais de réputation plus performant. De plus, Xvid ne supporte pas le Advanced Simple profil. C'est le plus gros projet alternatif à l'algorithme de Divxnetworks.
Xvid utilise l'algorithme de block matching PMVFAST, algorithme rapide et possèdant une bonne qualité visuelle.
4.1.2.3. FFmpeg
FFmpeg 12 est une implémentation opensource récente qui prévoit les fonctionnalités suivantes: encodeur/décodeur mpeg4, ainsi que serveur de streaming via http (FFserver). Cette dernière partie n'est pas opérationnelle mais se développe rapidement. L'encodage peut être fait en temps réel. FFmpeg est donc une solution intéressante et l'algorithme mérite d'être étudié. Une fois les sources compilées, on obtient la librairie libavcodec.
FFmpeg possède une interface graphique optionnelle: Xffmpeg. Il existe également un module d'export FFmpeg pour QuickTime utilisant la librairie: FFmpeg for QT (librairie libavqt).
Concernant les algorithmes de block matching, FFmpeg permet l'utilisation de plusieurs méthodes: Full Search (utilisée en high quality), une méthode 2Dlogarithmique, et la méthode PHODS (Parallel Hierarchical One-Dimensional Search). La méthode 2Dlogarithmique est utilisée dans l'encodage de séquences "classiques".
4.2. mise en oeuvre des tests
4.2.1. Compression des flux
4.2.1.1. Transcode
L'encodage sera fait via transcode [24, 25], un outil de transformation de flux vidéo sous licence GPL. Transcode utilise plusieurs librairies de codage/décodage video et fait la liaison entre ces modules. Il offre une couche d'abstraction au dessus des outils de traitement.
Quel que soit le format, transcode démultiplexe la vidéo de l'audio pour permettre des traitements séparés. Puis des modules d'import et d'export sont sélectionnables pour manipuler les objets vidéo dans les formats désirés. Le gros intérêt de transcode est sa souplesse: il possède un repertoire contenant toutes les librairies utilisées sous forme de librairies dynamiques pour les modules d'entrée et de sortie. Transcode possède les librairies pour les formats suivants:
-
Modules d'entrée: (librairies import_XXX.so)
DV, DVD, mjpeg, mpeg2, AVI, divx
-
Modules de sortie: (librairies export_XXX.so)
divx4, divx5, ffmpeg4, mjpeg, opendivx, xvid, WAV, PCM.
Cette liste n'est pas exhaustive, il est possible de rajouter ses propres modules d'import ou d'export.
Transcode est donc très versatile, mais il possède également de nombreuses fonctions de traitement pour l'encodage ou la transformation de flux vidéo: il permet de choisir lors de l'encodage le framerate, le bitrate et la résolution du fichier ensortie. L'utilitaire tcprobe permet de connaitre le bitrate adéquat pour une taille de fichier donnée.
4.2.1.2. encodage
transcode -V -i movie.m2v -o movie.avi -y divx4 -R 1(production d'un fichier log contenant les statistiques sur la complexité des frame)
transcode -V -i movie.m2v -o movie.avi -y divx4 -R 2
transcode -i movie.avi -y ppm
nom_fichier désigne le nom du fichier m2v à encoder sans l'extension. codec est l'un des codecs suivants: xvid, ffmpeg, divx4, ou all (encodage avec les trois codecs.)
C'est à partir de ces images qu'on va pouvoir comparer la qualité d'encodage. La comparaison est effectuée avec PIL: Python ImageLib.
4.2.2. Comparaison des flux
4.2.2.1. Outil de comparaison: PIL
PIL. Python Image Library[26] est une librairie de traitement d'image pour le langage de script python. Cette librairie supporte de nombreux formats d'image: PNG, BMP, JPEG, GIF, etc, et permet aussi de créer et manipuler ses propres formats. PIL possède des fonctions évoluées pour l'affichage (via XV) et le traitement des images. Il offre la possibilité d'appliquer des filtres, d'effectuer des opérations entre deux images, ou d'effectuer des transformations (redimensionnement, rotation, transformation affine,...). Avec les librairies Numeric et gracePlot, il est possible d'obtenir des fonctions statistiques ainsi que des histogrammes des images utilisées.
La classe Image offre les opérations classiques de manipulation d'image: ouverture, création, etc, ainsi que les opérations de rassemblement, de mélange entre deux images. La classe ImageChops permet les opérations entre les images: différence, ajout d'un offset, opérations logiques, etc. Il est utile de compiler les modules Numeric et gracePlot pour accéder à des fonctions de traitement plus évoluées. Comme dans Matlab ou Mathematica, on a alors un GUI. Certaines de ces fonctions nous serons nécessaires; voici les fonctions utilisées pour la comparaison d'images:
-
open("nom_fichier"): ouverture d'une image. Le format de celle ci (PPM) est automatiquement détecté. (fonction de la classe Image)
-
Image.convert("mode"): cette fonction renvoie une copie de l'image convertie au format désiré. Les images au format PPM sont passée en niveau de gris grâce à cette fonction, de manière à obtenir la luminance des pixels.
-
image transformée = image.point(fonction_affine): application d'une transformation affine sur l'image.
-
Image.show(): affiche une image. Cette fonction lance xv, un utilitaire de visualisation d'image.
-
ImageChops.difference(image_référence,image_encodée): la fonction difference de la classe ImageChops renvoie une image dont la valeur des pixels correspond à la différence pixel à pixel des deux images.
Différence entre deux images séparées de 15 frames issues du flux de référence. Cette image à été préalablement amplifiée par la fonction point par une fonction affine x -> x*10 pour accentuer les différences et les rendres plus visibles. (Cf. fichier Section B.1 imagediff.py)
-
Image.histogram(): cette fonction affiche l'histogramme d'une image. L'histogramme comporte 256 valeur en niveau de gris, ou 3*256 = 768 en RGB. cette fonction nécessite les modules Numeric et gracePlot.



moindres carrés avec PIL. Il faut définir une fonction effectuant les moindres carrés entre deux images. voici le script renvoyant la valeur voulue:
def rmsdiff(im1, im2):
#on se sert de l'histogramme
h = ImageChops.difference(im1, im2).histogram()
# formule
return math.sqrt(reduce(operator.add,
map(lambda h, i: h*(i**2), h, range(256))
) / (float(im1.size[0]) * im1.size[1]))
Le critère des moindres carrés donne un bon aperçu de la différence existante entre deux images.
Pour estimer l'erreur résiduelle sur une séquence de test, on somme l'erreur des moindres carrés sur toutes les images constituant la séquence.
différence d'histogrammes. pour obtenir la répartition de l'erreur, on soustrait l'histogramme de l'image en codé à l'histogramme de l'image de départ, en répétant l'opération pour toutes les images du flux. Ces histogrammes sont en suite additionnés. On connait alors le nombre de pixels comportant une erreur d'une valeur donnée.

4.3. Résultats
4.3.1. Moindres carrés
-
mobile: séquence comportant des mouvements de translation simultannée dans plusieurs directions sur des objets précis.
-
flower: long travelling horizontal sur une texture complexe.
Tableau 4-1. erreurs des moindres carrés
| Séquence | Xvid | FFmpeg | DivX4 |
|---|---|---|---|
| tennis, 6.0 Mbps | 3399 | 3341 | 3667 |
| susie, 6.0 Mbps | 1447 | 1450 | 1453 |
| mobile, 6.0 Mbps | 5723 | 5814 | 5995 |
| flower, 6.0 Mbps | 2167 | 2191 | 2217 |
4.3.2. Histogrammes des erreurs

(Ces histogrammes ont été générés par le fichier somme.py )
Les résultats semblent cohérents: la répartition des erreurs montre un grand nombre de petites erreurs (différence de luminance proche de 0), quantité qui décroit au fur et à mesure que l'erreur augmente. On a peu de très grosses erreurs: les écarts de luminance supérieur à 25 sont peu nombreux.
Le but de ces test est de comparer les trois algorithmes, et Il est difficile de tirer des conclusions de ces trois histogrammes: on voit des différences mais il est il est impossible de les quantifier. leur aspect global reste trop similaire.
On décide donc de calculer les différences entre ces trois histogrammes par une soustraction d'histogrammes (soustraction niveau de gris à niveau de gris). On aura la répartition des différences entre les algorithmes. Pour une bonne comparaison, on présente pour un algorithme:
-
L'histogramme "classique" des erreurs entre le flux de référence et le flux encodé sur une séquence.
-
La différence des erreurs obtenues entre l'algorithme et ses deux concurrents. On peut alors nettement comparer les algorithmes.
Nous présentons les histogrammes les plus "parlants". L'intégralité des résultats est en annexe. Ils sont constitués pour chaque algorithme des histogrammes de chaque séquence et de la différence avec les deux autres algorithmes. Tous les histogrammes possèdent la même échelle en abscisse (erreur de luminance: 0.5 - 35.5) mais pas forcément en ordonnée.


Bibliographie
MPEG
[1] site du MPEG.
[2] Two-pass MPEG-2 variable-bit-rate en coding, P. H. Westerlink, R. Rajagopalan, C. A. Gonzales, 1999 fichier pdf.
[3] Overview of the MPEG4 standard, Rob Koenen, ISO, 2002.
[4] On the use of layers for video coding and object manipulation, L. Torres, D. Garcia, A. Mates, 1997 fichier ps.
[5] Estimation de mouvement avec segmentation de blocs en codage d'images, A. Ouerfelli et H. Vu Thien, Laboratoire Electronique et Communication, Conservatoire National des Arts et metiers..
[6] Mpeg4 Industry Forum.
[8] Project Mayo.
[9] DivXNetworks.
[10] DivX.com.
[11] XviD.org.
Compensation de mouvement
[13] MPEG, Images animées, compensation de mouvement, J. Leroux, 2001. Site web.
[14] Motion compensation, Woobin Lee, 1995. site web.
[15] Three Step Search Algorithm, Colin Manning. site web.
[16] Predictive Diamond Search Algorithm: diamond algorithm et predictive diamond algorithm, A.M. Tourapis, G. Shen, M. L. Liou, O. C. Au, I. Ahmad, 2000. fichier pdf.
[17] "Predictive Motion Vector Fast Search Algorithm technique", A.M. Tourapis, G. Shen, M. L. Liou. fichier pdf.
[18] "comparaison des algorithmes PMVFAST, Full Search", Oscar Au. site web.
[19] "Motion Compensated Video Compression Overview", Colin Manning. site web.
[20] "Codage des objets virtuels", 1999. site web.
[21] "Hierarchical Block Matching Algorithms", Colin Manning. site web.
[22] "Variable Size Block-Matching" (VSBM), Multimedia Coding Group. Variable Size Block-Matching (VSBM).
[23] "An Adaptive Center (Radar) Zonal Based Algorithm for Motion Estimation", A.M. Tourapis, Oscar Au, M. L. Liou, 1999 fichier pdf.
Outils de tests
[24] Transcode, le couteau suisse de la vidéo, Guillaume Rousse, 2002. site web.
[25] Transcode: Linux Video Stream Processing Tool. site web.
[26] Python Imaging Library. site web.








Annexe B. Annexe: fichier de script python
B.1. imagediff.py: différence de deux images et résultat dans une troisième
import os, sys
import Image, ImageChops
import math, operator
def compare():
# chargement des deux images à comparer issues du flux non encodé
img_REF1 = Image.open("/opt/videos/mobl_060/ppm_REF/000010.ppm")
img_REF2 = Image.open("/opt/videos/mobl_060/ppm_ffmpeg/000010.ppm")
if img_REF1.size == img_REF2.size:
diff_xvid = ImageChops.difference(img_REF1,img_REF2)
diff_xvid = diff_xvid.point(lambda i: i*10)
diff_xvid.show()
compare()
B.2. histo.py: affichage de l'histogramme d'une image
import os, sys
import Image, ImageChops
from gracePlot import gracePlot
def histogramme():
p = gracePlot() # pour les histogrammes
# chargement image issue du flux non encodé
img_REF1 = Image.open("/opt/videos/tens_060/ppm_REF/000000.ppm")
#conversion en niveaux de gris
img_REF = img_REF.convert("L")
#génération histogramme, et affichage
h = img_REF.histogram()
p.histoPlot(h)
p.title('histogramme')
histogramme()
B.3. somme.py
import os, sys
import Image, ImageChops
import math, operator
from gracePlot import gracePlot
def compare(nomfic, nb):
p1 = gracePlot() # pour les histogrammes
#p2 = gracePlot()
#p3 = gracePlot()
indices = range(nb) # nombre d'image à comparer
nomfic="tens_060"
# Initialisation des histogrammes
histo_xvid = [0] * 256
histo_ffmpeg = [0] * 256
histo_divx4 = [0] * 256
for j in indices :
nom = "000%d.ppm" %(j)
if j < 100:
nom = "0000%d.ppm" %(j)
if j < 10:
nom = "00000%d.ppm" %(j)
# chargement image issue du flux non encodé
img_REF = Image.open("/opt/videos/"+nomfic+"/ppm_REF/" + nom)
# chargement images des trois flux encodés
img_xvid = Image.open("/opt/videos/"+nomfic+"/ppm_xvid/"+ nom)
img_ffmpeg = Image.open("/opt/videos/"+nomfic+"/ppm_ffmpeg/"+ nom)
img_divx4 = Image.open("/opt/videos/"+nomfic+"/ppm_divx4/"+ nom)
# conversion des images en luminance
img_REF = img_REF.convert("L")
img_xvid = img_xvid.convert("L")
img_ffmpeg = img_ffmpeg.convert("L")
img_divx4 = img_divx4.convert("L")
if img_REF.size == img_xvid.size:
diff_xvid = ImageChops.difference(img_REF,img_xvid)
h = diff_xvid.histogram()
histo_xvid = add(histo_xvid,h)
if img_REF.size == img_ffmpeg.size:
diff_ffmpeg = ImageChops.difference(img_REF,img_ffmpeg)
h = diff_ffmpeg.histogram()
histo_ffmpeg = add(histo_ffmpeg,h)
if img_REF.size == img_xvid.size:
diff_divx4 = ImageChops.difference(img_REF,img_divx4)
h = diff_divx4.histogram()
histo_divx4 = add(histo_divx4,h)
#histo_x_moins_d = sub(histo_xvid,histo_divx4)
p1.multi(1,3)
p1.focus(0,0)
p1.title('xvid')
p1.histoPlot(histo_xvid)
p1.xlimit(0, 30)
p1.focus(0,1)
p1.histoPlot(histo_ffmpeg)
p1.title('ffmpeg')
p1.xlimit(0, 30)
p1.focus(0,2)
p1.histoPlot(histo_divx4)
p1.title('divx4')
p1.xlimit(0, 30)
#p1.histoPlot(histo_x_moins_d)
# fonction qui additionne deux histogrammes
def add(self, other):
return map(lambda x,y: x+y, self, other)
def sub(self, other):
return map(lambda x,y: x-y, self, other)
compare("flwr_060", 50)